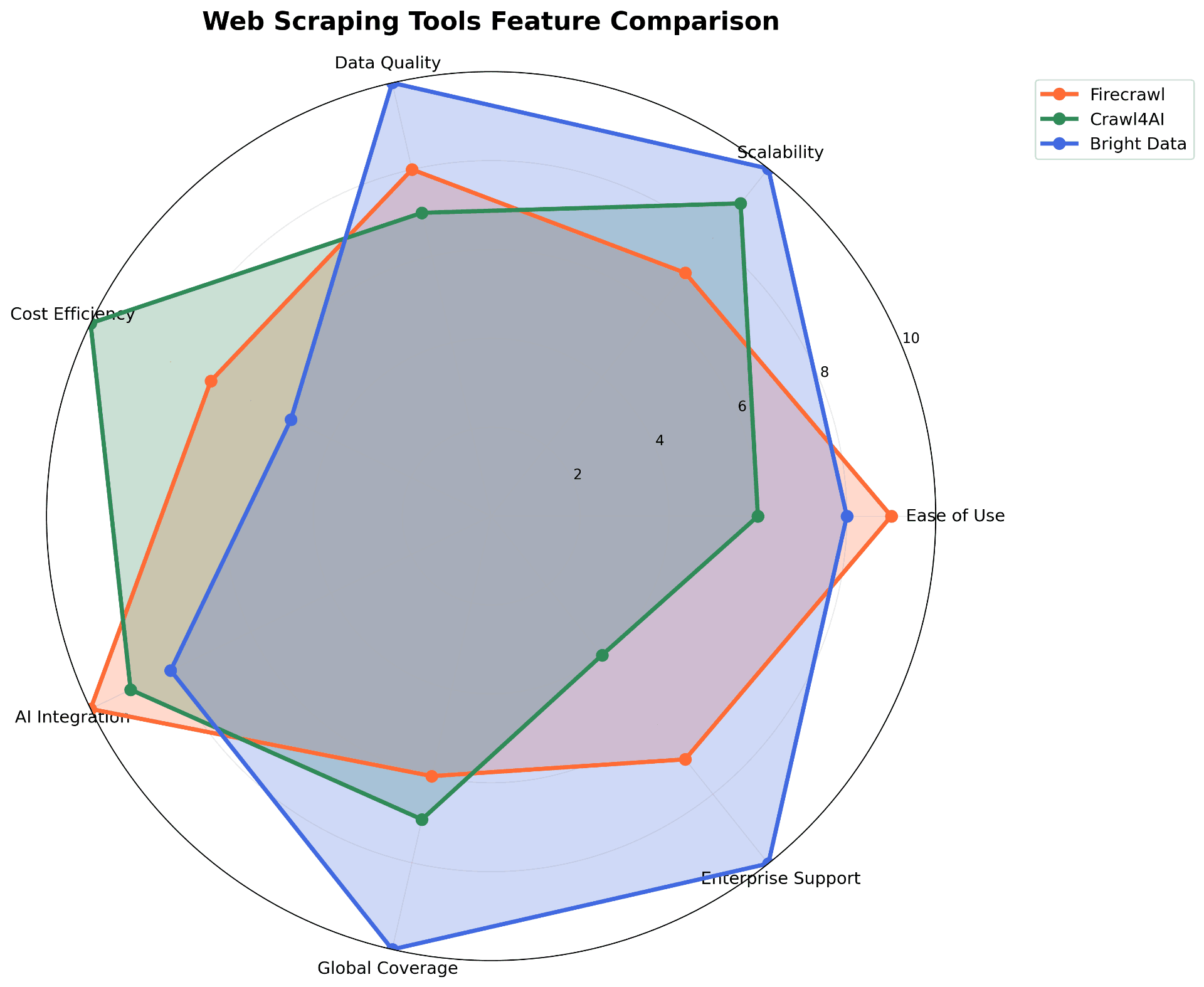
在快速演進的 AI 生態系統中,高品質資料不僅僅是資產——它是競爭優勢的生命線。無論您是在微調基礎模型、架構 RAG 管道,還是驅動即時分析,網路資料擷取都是您 AI 技術堆疊的基礎層。 今天,我們將三個強大的網路爬蟲解決方案放在顯微鏡下:Firecrawl、Crawl4AI 和 Bright Data。我們將剖析它們在傳統網路爬蟲和尖端 AI 資料來源方面的能力,幫助您為技術堆疊做出正確選擇。 認識競爭者 Firecrawl:LLM 的耳語者 Firecrawl 為 LLM 工作流程開闢了獨特的利基市場,在此過程中獲得了超過 31,000 個 GitHub 星標。是什麼讓它與眾不同?它專注於將雜亂的網路內容轉換為乾淨、LLM 友好的資料格式。 核心驅動力: 🎯 LLM 優先架構:乾淨的 Markdown 輸出 ⚡ 智慧渲染引擎:處理 JavaScript 密集型網站 🔧 雙重部署選項:SaaS 便利性或自主託管控制 💰 免費增值模式:500 積分起步,每月 $16 起擴展 Crawl4AI:開源強者 擁有超過 46,000 個 GitHub 星標的 Crawl4AI 代表了社群對企業級網路爬蟲的回應。從頭開始為 AI 工作負載構建,它是資料擷取的瑞士軍刀。 核心優勢: 🆓 永遠免費:完全開源,無任何附加條件 🤖 AI 原生設計:由機器學習驅動的多重擷取策略 ⚡ 非同步優先架構:為高並發支援而構建的擴展性 🎛️ 無限客製化:適用於複雜使用案例的可擴展框架 Bright Data:企業巨擘 自 2014 年以來,Bright Data 一直是企業網路資料收集領域無可爭議的領導者。他們的秘密武器?一個令人驚嘆的代理基礎設施,橫跨地球上幾乎每個國家的 1.5 億個 IP。 企業 DNA: 🌍 全球代理霸權:業界最大網路 🏢 白手套服務:企業 SLA 和專屬支援 📊 端到端平台:從資料發現到交付 💼 全天候支援:24/7 技術協助 AI 資料軍備競賽:真正重要的地方 現代 AI 系統只有消費的資料那麼好。但這裡有個陷阱——並非所有資料都是平等創造的。今天的 AI 應用需要外科手術般的精確度:完美的品質、標準化格式和智慧預處理。讓我們看看我們的三個競爭者在這個高風險競技場中如何表現。 資料品質:成敗關鍵因素 Bright Data 奪得桂冠 在資料完整性方面,Bright Data 不僅滿足標準——它設定標準。他們的品質保證管道堪稱工業級: 三層驗證:來源驗證 → 收集監控 → 輸出驗證 SLA 支援的準確性:99.95% 資料保真度保證 即時品質閘道:持續監控與即時異常檢測 Firecrawl 憑藉智慧內容解析表現出色,特別是在文字密集型應用中。其雜訊過濾演算法在分離信號與雜訊方面表現卓越。Crawl4AI 的品質故事更加微妙——它能夠產生卓越結果,但成功取決於適當的配置和實施專業知識。 AI 優先設計:專用構建 vs. 改裝 Firecrawl 的 LLM 甜蜜點: 源頭雜訊消除:自動過濾導航、廣告和樣板內容 結構保存:在 Markdown 中維護語義層次 框架就緒:與 LangChain、LlamaIndex 等原生整合 Crawl4AI 的靈活性優勢: 多策略擷取:CSS 選擇器、XPath 和 LLM 驅動解析 智慧分塊:針對最佳令牌利用的內建策略 向量就緒輸出:內建餘弦相似度和 BM25 演算法 Bright Data 的生態系統策略: 預處理資料集:120+ 垂直領域的 AI 就緒格式 即時串流:線上學習場景的即時資料饋送 客製化管道:針對特定 AI 使用案例的量身定制處理工作流程 應用場景相容性 不同的 AI 應用有不同的資料來源需求: 使用案例 Firecrawl Crawl4AI Bright Data LLM 訓練 ⭐⭐⭐⭐⭐ ⭐⭐⭐⭐ ⭐⭐⭐⭐⭐ RAG 應用 ⭐⭐⭐⭐⭐ ⭐⭐⭐⭐ ⭐⭐⭐ 模型微調 ⭐⭐⭐⭐ ⭐⭐⭐ ⭐⭐⭐⭐⭐ 資料集構建 ⭐⭐⭐⭐ ⭐⭐⭐⭐⭐ ⭐⭐⭐⭐⭐ 即時推理 ⭐⭐⭐ ⭐⭐⭐⭐ ⭐⭐⭐⭐⭐ 資料經濟學:ROI 分析 免費方案現實檢查 Crawl4AI:無限使用,零成本(但基礎設施麻煩自負) Firecrawl:500 積分試水溫 Bright Data:無免費方案,但有慷慨的試用計劃 付費方案定位 Firecrawl:每月 $16 入門點(3,000 積分) Crawl4AI:永遠免費,但要考慮 DevOps 開銷 Bright Data:基於使用量的企業定價 隱藏成本方程式 大多數比較都錯過了這一點——總擁有成本(TCO): Crawl4AI 的「免費」現實: 基礎設施配置和擴展 DevOps 工程時間 監控和維護開銷 可靠性風險管理 Bright Data 的價值主張: 零基礎設施管理 內建合規和法律保護 99.95% 正常運行時間 SLA 白手套技術支援 為什麼 Bright Data 主導企業遊戲 1. 真正可擴展的全球基礎設施 Bright Data 運營著只能被描述為網際網路最大代理星座的東西: 1.5 億個 IP:橫跨每個有人居住的大陸 多層代理類型:住宅、資料中心、行動和 ISP 智慧地理路由:區域資料存取的自動最佳化 這不僅僅是關於數字——這是關於能力: 在源頭存取地理限制內容 繞過複雜的反機器人措施 收集真實、本地化的使用者體驗資料 2. 夜晚安心的合規性 在今天的監管環境中,資料合規不是可選的——它是存在性的。Bright Data 將合規性構建到他們的 DNA 中: GDPR 和 CCPA 認證:不僅合規,而且經過審計和驗證 透明同意機制:每個資料點都經過道德採購 法律盾牌:為企業客戶提供全面賠償 審計軌跡:監管報告的完整資料血統 3. AI 資料工廠 Bright Data 不僅僅是爬蟲工具——它是一個完整的 AI 資料製造平台: 資料市場:120+ 行業垂直領域的生產就緒資料集 客製化資料工程:針對定制需求的專屬團隊 API 優先架構:與現有 ML 管道的無縫整合 即時資料串流:動態 AI 應用的即時饋送 4. 經得起嚴格審查的品質 Bright Data 已將資料品質工業化: 多維驗證:準確性、完整性、一致性、新鮮度 自動化 QA 管道:即時異常檢測和修正 人在迴路驗證:關鍵驗證的專業資料工程師 品質 SLA:由金錢懲罰支援的合約保證 判決:選擇您的資料武器 獨立開發者和自力更生的新創公司 路徑:Crawl4AI → Firecrawl 從 Crawl4AI 開始進行概念驗證和學習 當需要可靠性而無基礎設施複雜性時升級到 Firecrawl 擴展期和成長型公司 選擇:Firecrawl vs. Bright Data 簡單文字擷取需求:Firecrawl 的 LLM 最佳化獲勝 全球資料需求或品質關鍵應用:Bright Data 的企業實力 企業和財富 500 強 明確贏家:Bright Data 有 SLA 支援的關鍵任務可靠性 無地理限制的全球資料存取 全面的合規框架 專屬技術客戶管理 AI 資料基礎設施的未來 AI 資料環境正朝著幾個關鍵範式演進: 自主資料智慧:自我最佳化收集策略 亞秒級延遲需求:邊緣運算資料存取模式 零容忍品質標準:工業規模的自動化驗證 隱私設計架構:構建到資料管道中的合規性 Bright Data 獨特定位,憑藉在基礎設施、服務交付和監管框架方面的全面優勢來引領這一演進。 底線 雖然每個工具都服務於其利基市場,Bright Data 成為 AI 優先資料策略的明確領導者: ✅ 規模:業界領先的代理基礎設施 ✅ 品質:生產級資料驗證 ✅ 生態系統:完整的 AI 資料平台 ✅ 支援:企業級服務交付 ✅ 合規性:防彈監管框架 對於大規模構建 AI 的組織,Bright Data 不僅僅是供應商——它是策略性資料基礎設施合作夥伴。在資料品質決定 AI 成功的時代,選擇具有經過驗證的企業能力的平台不僅僅是明智的——它對競爭生存至關重要。 準備好為您的 AI 資料管道增壓了嗎?選擇很明確,但實施才是魔法發生的地方。